
{kind=link}
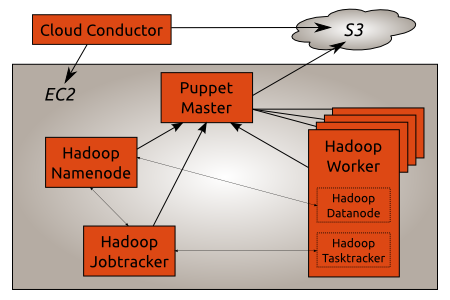
A Hadoop Cluster running on EC2/UEC deployed by puppet on Ubuntu Maverick.
How it works
The Cloud Conductor is located outside the AWS infrastructure as it needs AWS credentials to start new instances. The Puppet Master runs in EC2 and uses S3 to check which clients it should accept.
The Hadoop Namenode, Jobtracker and Worker are also running in EC2. The Puppet Master automatically configures them so that each Worker can connect to the Namenode and Jobtracker.
The Puppet Master uses Stored Configuration to distribute configuration between all the Hadoop components. For example the Namenode IP address is automatically pushed to the Jobtracker and the Worker nodes so that they can connect to the Namenode.
Ubuntu Maverick is used since Puppet 2.6 is required. The excellent Cloudera CDH3 Beta2 packages provide the base Hadoop foundation.
Puppet recipes and the Cloud Conductor scripts are available in a bzr branch on Launchpad.
Setup the Cloud Conductor
The first part of the Cloud Conductor is the start_instance.py script. It takes care of starting new instances in EC2 and registering them in S3. Its configuration lives in start_instance.yaml. Both files are located in the conductor directory of the bzr branch.
The following options are available on the cloud conductor:
- s3_bucket_name: Sets the name of the S3 bucket used to store the list of instances started by the Cloud Conductor. The Puppet Master uses the same bucket to check which Puppet Client should be accepted.
- ami_id: Sets the id of the AMI the Cloud Conductor will use to start new instances.
- cloud_init: Sets specific cloud-init parameters. All of the puppet client configuration is defined here.Public ssh keys (for example from Launchpad) can be configured using the ssh_import_id option. The cloud-init documentation has more information [1] about what can be configured when starting new instances.
A sample start_instance.yaml file looks like this:
# Name of the S3 bucket to use to store the certname of started instances
s3_bucket_name: mathiaz-hadoop-cluster
# Base AMI id to use to start all instances
ami_id: ami-c210e5ab
# Extra information passed to cloud-init when starting new instances
# see cloud-init documentation for available options.
cloud_init: &site-cloud-init
ssh_import_id: mathiazOnce the Cloud Conductor is configured a Puppet Master can be started:
./start_instance.py puppetmasterSetup the Puppet Master
Once the instance has started and its ssh fingerprints can be verified the puppet recipes are deployed on the Puppet Master:
bzr branch lp:~mathiaz/+junk/hadoop-cluster-puppet-conf ~/puppet/
sudo mv /etc/puppet/ /etc/old.puppet
sudo mv ~/puppet/ /etc/The S3 bucket name is set in the Puppet Master configuration /etc/puppet/manifests/puppetmaster.pp:
node default {
class {
"puppet::ca":
node_bucket => "https://mathiaz-hadoop-cluster.s3.amazonaws.com";
}
}And finally the Puppet Master installation can be completed by puppet itself:
sudo puppet apply /etc/puppet/manifests/puppetmaster.ppA Puppet Master is now running into EC2 with all the recipes required to deploy the different components of a Hadoop Cluster.
Update the Cloud Conductor configuration
Since the Cloud Conductor starts instances that will connect to the Puppet Master it needs to know some information about the Puppet Master:
- the Puppet Master internal IP address or DNS name. For example the DNS name of the instance (which is the FQDN) can be used.
- the Puppet Master certificate (located in /var/lib/puppet/ssl/ca/ca_crt.pem):
On the Cloud Conductor the information gathered on the Puppet Master is added to start_instance.yaml:
agent:
# Puppet server hostname or IP
# In EC2 the Private DNS of the instance should be used
server: domU-12-31-38-00-35-98.compute-1.internal
# NB: the certname will automatically be added by start_instance.py
# when a new instance is started.
# Puppetmaster ca certificate
# located in /var/lib/puppet/ssl/ca/ca_crt.pem on the puppetmaster system
ca_cert: |
-----BEGIN CERTIFICATE-----
MIICFzCCAYCgAwIBAgIBATANBgkqhkiG9w0BAQUFADAUMRIwEAYDVQQDDAlQdXBw
[ ... ]
k0r/nTX6Tmr8TTU=
-----END CERTIFICATE-----Start the Hadoop Namenode
Once the Puppet Master and Cloud Conductor are configured the Hadoop Cluster can be deployed. First in line is the Hadoop Namenode:
./start_instance.py namenodeAfter a few minutes the Namenode puppet client requests a certificate:
puppet-master[7397]: Starting Puppet master version 2.6.1
puppet-master[7397]: 53b0b7bf-723c-4a0f-b4b1-082ebec84041 has a waiting certificate requestThe Master signs the CSR:
CRON[8542]: (root) CMD (/usr/local/bin/check_csr https://mathiaz-hadoop-cluster.s3.amazonaws.com)
check_csr[8543]: INFO: Signing request: 53b0b7bf-723c-4a0f-b4b1-082ebec84041And finally the Master compiles the manifest for the Namenode:
node_classifier[8989]: DEBUG: Checking url https://mathiaz-hadoop-cluster.s3.amazonaws.com/53b0b7bf-723c-4a0f-b4b1-082ebec84041
node_classifier[8989]: INFO: Getting node configuration: 53b0b7bf-723c-4a0f-b4b1-082ebec84041
node_classifier[8989]: DEBUG: Node configuration (53b0b7bf-723c-4a0f-b4b1-082ebec84041): classes: ['hadoop::namenode']
puppet-master[7397]: Puppet::Parser::AST::Resource failed with error ArgumentError: Could not find stage hadoop-base specified by Class[Hadoop::Base] at /etc/puppet/modules/hadoop/manifests/init.pp:142 on node 53b0b7bf-723c-4a0f-b4b1-082ebec84041Unfortunately there is a bug related to puppet stages. As a workaround the puppet agent can be restarted:
sudo /etc/init.d/puppet restartLooking at the syslog file on the Namenode the Puppet Agent installs and configures the Hadoop Namenode:
puppet-agent[1795]: Starting Puppet client version 2.6.1
puppet-agent[1795]: (/Stage[apt]/Hadoop::Apt/Apt::Key[cloudera]/File[/etc/apt/cloudera.key]/ensure) defined content as '{md5}dc59b632a1ce2ad325c40d0ba4a4927e'
puppet-agent[1795]: (/Stage[apt]/Hadoop::Apt/Apt::Key[cloudera]/Exec[import apt key cloudera]) Triggered 'refresh' from 1 events
puppet-agent[1795]: (/Stage[apt]/Hadoop::Apt/Apt::Sources_list[canonical]/File[/etc/apt/sources.list.d/canonical.list]/ensure) created
puppet-agent[1795]: (/Stage[apt]/Hadoop::Apt/Apt::Sources_list[cloudera]/File[/etc/apt/sources.list.d/cloudera.list]/ensure) created
puppet-agent[1795]: (/Stage[apt]/Apt::Apt/Exec[apt-get_update]) Triggered 'refresh' from 3 eventsThe first stage of the puppet run sets up the Canonical partner archive and the Cloudera archive. The Sun JVM is pulled from the Canonical archive while Hadoop packages are downloaded from the Cloudera archive.
The following stage creates a common Hadoop configuration:
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/var/cache/debconf/sun-java6.seeds]/ensure) defined content as '{md5}1e3a7ac4c2dc9e9c3a1ae9ab2c040794'
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/Package[sun-java6-bin]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/Package[hadoop-0.20]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/var/lib/hadoop-0.20/dfs]/ensure) created
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/etc/hadoop-0.20/conf.puppet]/ensure) created
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/etc/hadoop-0.20/conf.puppet/hdfs-site.xml]/ensure) defined content as '{md5}1f9788fceffdd1b2300c06160e7c364e'
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/Exec[/usr/sbin/update-alternatives --install /etc/hadoop-0.20/conf hadoop-0.20-conf /etc/hadoop-0.20/conf.puppet 15]) Triggered 'refresh' from 1 events
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/etc/default/hadoop-0.20]/content) content changed '{md5}578894d1b3f7d636187955c15b8edb09' to '{md5}ecb699397751cbaec1b9ac8b2dd0b9c3'Finally the Hadoop Namenode is configured:
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/Package[hadoop-0.20-namenode]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/File[hadoop-core-site]/ensure) defined content as '{md5}2f2445bf3d4e26f5ceb3c32047b19419'
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/File[/var/lib/hadoop-0.20/dfs/name]/ensure) created
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/Exec[format-dfs]) Triggered 'refresh' from 1 events
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/Service[hadoop-0.20-namenode]/ensure) ensure changed 'stopped' to 'running'
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/Service[hadoop-0.20-namenode]) Failed to call refresh: Could not start Service[hadoop-0.20-namenode]: Execution of '/etc/init.d/hadoop-0.20-namenode start' returned 1: at /etc/puppet/modules/hadoop/manifests/init.pp:177There is another bug in the Hadoop init script this time: the Namenode cannot be started. The puppet agent can be restarted or the next puppet run will start it:
sudo /etc/init.d/puppet restartThe Namenode daemon is running and logs information to its log file in /var/log/hadoop/hadoop-hadoop-namenode-*.log:
[...]
INFO org.apache.hadoop.hdfs.server.namenode.NameNode: Web-server up at: 0.0.0.0:50070
[...]
INFO org.apache.hadoop.ipc.Server: IPC Server handler 9 on 8200: starting
INFO org.apache.hadoop.ipc.Server: IPC Server handler 8 on 8200: startingStart the Hadoop Jobtracker
The next component to start is the Hadoop Jobtracker:
./start_instance.py jobtrackerAfter some time the Puppet Master compiles the Jobtracker manifest:
DEBUG: Checking url https://mathiaz-hadoop-cluster.s3.amazonaws.com/2faa4de9-c708-45ab-a515-ae041a9d0239
node_classifier[30683]: INFO: Getting node configuration: 2faa4de9-c708-45ab-a515-ae041a9d0239
node_classifier[30683]: DEBUG: Node configuration (2faa4de9-c708-45ab-a515-ae041a9d0239): classes: ['hadoop::jobtracker']
puppet-master[23542]: Compiled catalog for 2faa4de9-c708-45ab-a515-ae041a9d0239 in environment production in 2.00 secondsOn the instance the puppet agent configures the Hadoop Jobtracker:
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/File[hadoop-mapred-site]/ensure) defined content as '{md5}af3b65a08df03e14305cc5fd56674867'
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/File[hadoop-core-site]/ensure) defined content as '{md5}2f2445bf3d4e26f5ceb3c32047b19419'
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/Package[hadoop-0.20-jobtracker]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/Service[hadoop-0.20-jobtracker]/ensure) ensure changed 'stopped' to 'running'
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/Service[hadoop-0.20-jobtracker]) Failed to call refresh: Could not start Service[hadoop-0.20-jobtracker]: Execution of '/etc/init.d/hadoop-0.20-jobtracker start' returned 1: at /etc/puppet/modules/hadoop/manifests/init.pp:135There is the same bug in the init script. Let's restart the puppet agent:
sudo /etc/init.d/puppet restartThe Jobtracker connects to the Namenode and error messages are logged on a regular basis to both the Namenode and Jobtracker log files:
INFO org.apache.hadoop.ipc.Server: IPC Server handler 7 on 8200, call
addBlock(/hadoop/mapred/system/jobtracker.info, DFSClient_-268101966, null)
from 10.122.183.121:54322: error: java.io.IOException: File
/hadoop/mapred/system/jobtracker.info could only be replicated to 0 nodes,
instead of 1
java.io.IOException: File /hadoop/mapred/system/jobtracker.info could only be
replicated to 0 nodes, instead of 1This is normal as there aren't any Datanode daemon available for data replication.
Start Hadoop workers
It's now time to start the Hadoop Worker to get an operational Hadoop Cluster:
./start_instance.py workerThe Hadoop Worker holds both a Data node and a Task tracker. The Puppet agent configures them to talk to the Namenode and Job tracker respectively.
After some time the Puppet Master compiles the catalog for the Hadoop Worker:
node_classifier[8368]: DEBUG: Checking url https://mathiaz-hadoop-cluster.s3.amazonaws.com/b72a8f4d-55e6-4059-ac4b-26927f1a1016
node_classifier[8368]: INFO: Getting node configuration: b72a8f4d-55e6-4059-ac4b-26927f1a1016
node_classifier[8368]: DEBUG: Node configuration (b72a8f4d-55e6-4059-ac4b-26927f1a1016): classes: ['hadoop::worker']
puppet-master[23542]: Compiled catalog for b72a8f4d-55e6-4059-ac4b-26927f1a1016 in environment production in 0.18 secondsOn the instance the puppet agent installs the Hadoop worker:
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/File[hadoop-mapred-site]/ensure) defined content as '{md5}af3b65a08df03e14305cc5fd56674867'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Package[hadoop-0.20-datanode]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/File[/var/lib/hadoop-0.20/dfs/data]/ensure) created
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Package[hadoop-0.20-tasktracker]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/File[hadoop-core-site]/ensure) defined content as '{md5}2f2445bf3d4e26f5ceb3c32047b19419'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Service[hadoop-0.20-datanode]/ensure) ensure changed 'stopped' to 'running'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Service[hadoop-0.20-datanode]) Failed to call refresh: Could not start Service[hadoop-0.20-datanode]: Execution of '/etc/init.d/hadoop-0.20-datanode start' returned 1: at /etc/puppet/modules/hadoop/manifests/init.pp:103
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Service[hadoop-0.20-tasktracker]/ensure) ensure changed 'stopped' to 'running'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Service[hadoop-0.20-tasktracker]) Failed to call refresh: Could not start Service[hadoop-0.20-tasktracker]: Execution of '/etc/init.d/hadoop-0.20-tasktracker start' returned 1: at /etc/puppet/modules/hadoop/manifests/init.pp:103Again the same init script bug - let's restart the puppet agent:
sudo /etc/init.d/puppet restartOnce the worker is installed the Datanode daemon connects to the Namenode:
INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 10.249.187.5:50010 storage DS-2066068566-10.249.187.5-50010-1285276011214
INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/10.249.187.5:50010Similarly the Task Tracker daemon registers itself with the Jobtracker:
INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/domU-12-31-39-03-B8-F7.compute-1.internalThe Hadoop Cluster is up and running.
Conclusion
Once the initial setup of the Puppet master is done and the Hadoop Namenode and Jobtracker are up and running adding new Hadoop Workers is
just one command:
./start_instance.py workerPuppet automatically configures them to join the Hadoop Cluster.
Great work, works well for me!
ReplyDeleteThe discussion focuses on Hadoop deployment, distributed storage, and large-scale data processing architectures that form the foundation of modern analytics ecosystems. These concepts are closely associated with Big Data Projects, where technologies such as Hadoop, distributed computing, and scalable data platforms are used to manage and analyze massive datasets efficiently.
DeleteSince the article also involves deploying Hadoop in virtualized cloud environments, it highlights the growing relationship between distributed data systems and cloud infrastructure. Such implementations are highly relevant to Cloud Computing Projects, where scalable resource provisioning, virtualization, and infrastructure management play a key role in supporting modern data-intensive applications.
Wonderful post! Youve made some very astute observations and I am thankful for the the effort you have put into your
ReplyDeletewriting. Its clear that you know what you are talking about. I am looking forward to reading more of your sites content.
Hadoop training
ous web based learning applications give quality seminars on information science and furthermore give an authentication to it. ExcelR Data Science Courses
ReplyDeleteI am looking for and I love to post a comment that "The content of your post is awesome" Great work!
ReplyDeletebusiness analytics course
data analytics courses in mumbai
data science interview questions
data science course in mumbai
Nice Post ! really enjoyed reading this article. Thanks for sharing such detailed information.
ReplyDeleteAI Training in Hyderabad
Hi, Thanks for sharing wonderful articles....
ReplyDeleteAI Training In Hyderabad
Nice information thanks for sharing it’s very useful. This article gives me so much information.
ReplyDeleteAWS Training in Hyderabad
cool stuff you have and you keep overhaul every one of us
ReplyDeleteData Analyst Course
I am really enjoying reading your well written articles. It looks like you spend a lot of effort and time on your blog. I have bookmarked it and I am looking forward to reading new articles. Keep up the good work. data science training in Hyderabad
ReplyDeleteGlad to chat your blog, I seem to be forward to more reliable articles and I think we all wish to thank so many good articles, blog to share with us.
ReplyDeletedata analytics courses
Very nice blogs!!! i have to learning for lot of information for this site…Sharing for wonderful information. Thanks for sharing this valuable information to our vision. You have posted a trust worthy blog keep sharing,
ReplyDeleteData Science Training in Hyderabad
Data Science Course in Hyderabad
Excellent Blog! I would like to thank for the efforts you have made in writing this post. I am hoping the same best work from you in the future as well. I wanted to thank you for this websites! Thanks for sharing. Great websites!
ReplyDeletedata science certification
This is also a very good post which I really enjoyed reading. It is not every day that I have the possibility to see something like this..
ReplyDeletedata scientist online course
This is really a great information from your post.
ReplyDeleteDevOps Training in Hyderabad
DevOps Course in Hyderabad
Great info! I recently came across your blog and have been reading along. I thought I would leave my first comment. I don’t know what to say except that I have.
ReplyDeletefull stack developer course with placement
Thanks for sharing
ReplyDeleteShreyan IT, helps companies/employers get matched with talented candidates who meet their requirements. We provide staffing solutions for local, national, and global recruitment needs. Our goal is to assist job seekers in finding new positions while also assisting employers in finding the best applicant for their available positions.
Hi,
ReplyDeleteI appreciate this detailed guide on deploying a Hadoop cluster on EC2/UEC with Puppet and Ubuntu Maverick. It provides a comprehensive step-by-step approach, making it easier for those looking to set up their own Hadoop environment. Thanks for sharing!
Data Analytics Courses in Nashik
This article appears to provide a helpful guide on deploying a Hadoop cluster on EC2/UEC using Puppet and Ubuntu Maverick. Using automation tools like Puppet can simplify the process of setting up and managing Hadoop clusters, making it easier for developers and administrators to work with big data solutions.
ReplyDeleteData Analytics Courses In Kochi
Impressive deployment of a Hadoop cluster on EC2/UEC using Puppet and Ubuntu Maverick. Streamlined setup and automated configuration make this an efficient and valuable solution. Thank you.
ReplyDeleteData Analytics Courses In Dubai
This is really a great information. Thanks for sharing with us.
ReplyDeleteData Analytics Courses in Agra
This kind of knowledge-sharing is instrumental in enabling organizations to harness the full potential of their data. Thank you so much for sharing.
ReplyDeleteData Analytics Courses In Chennai
Thank you so much for providing a great tutorial on Deploying a Hadoop cluster on EC2/UEC with Puppet and Ubuntu Maverick. I was having some trouble related to this but after after reading your blog is is all cleared.
ReplyDeleteVisit - Data Analytics Courses in Delhi
good blog
ReplyDeleteData Analytics Courses In Vadodara
I am looking for and I love to post a comment that "The content of your post is awesome". I really enjoyed reading this article. Thanks for sharing such detailed information.
ReplyDeleteData science courses in Gurgaon
I’m really impressed by how detailed and informative this article is! The content is relevant, well-researched, and presented in a way that’s easy to absorb. Thanks for creating such a valuable resource.
ReplyDeleteData Analytics Courses in Delhi
Fantastic guide on deploying a Hadoop cluster! Your detailed instructions and insights on using Puppet with Ubuntu make complex setups more accessible. Keep sharing your expertise—it's invaluable for those venturing into big data!
ReplyDeleteData Science Courses in Singapore
ReplyDeleteThis article provides a comprehensive and detailed guide to deploying a Hadoop cluster on EC2 using Puppet and Ubuntu Maverick. It's fascinating to see how automation with Puppet simplifies the management of large-scale clusters, making it easier to set up and configure Hadoop components efficiently.
For those in Ghana interested in expanding their knowledge in big data and analytics, the data analytics courses offered by IIM Skills are a great opportunity. These courses equip learners with the essential skills needed for managing Hadoop environments and diving into the world of Big Data. Data Analytics Courses in Ghana
"Thanks for sharing this valuable information! The data science courses in Faridabad are a great resource for aspiring data scientists."
ReplyDeleteGreat guide on deploying a Hadoop cluster on EC2! I found the step-by-step instructions very helpful, especially the networking setup.
ReplyDeleteData science courses in Bhutan
I never thought of it that way before. The way you explained about deployoing hadoop cluster was intresting. Great job.
ReplyDeleteOnline Data Science Course
I will say you have done a great job writing this article. Very nice and well written.
ReplyDeleteData Science Courses in Hauz Khas
This article provides an excellent overview of deploying a Hadoop cluster on EC2 using Puppet and Ubuntu Maverick! The step-by-step approach, particularly the integration of the Cloud Conductor and Puppet Master, simplifies the deployment process significantly. I appreciate how you explained the configuration options for the Cloud Conductor, like s3_bucket_name and cloud_init, making it clear how to customize the setup for different needs.
ReplyDeleteData science courses in Mysore
"I just read about the Data Science Course in Dadar, and I’m really impressed! The course content looks comprehensive and perfect for anyone looking to break into the data science field. The emphasis on practical applications is a huge plus. Thanks for sharing this valuable resource!"
ReplyDeleteYour writing is so clear and concise. It makes learning new things a breeze.
ReplyDeleteData science courses in Thailand
The post on Mathiaz Blog about deploying a Hadoop cluster on EC2/UEC is very informative! It provides clear, step-by-step instructions that make the setup process accessible for users. The tips on configuration and best practices are particularly valuable for anyone looking to leverage cloud resources for big data applications. Thanks for sharing such useful insights!
ReplyDeleteData science courses in Bangalore.
Thank you for blog.
ReplyDeleteData science Courses in Germany
If you’re considering data science as a career and you’re based in Iraq, this post is a great place to start! The list of courses covers various aspects of data science, so you can find one that suits your needs and career aspirations. Be sure to check out the full list here—you won’t regret it!
ReplyDeleteGreat blog! Your explanation of deploying a Hadoop cluster using Puppet on EC2/UEC with Ubuntu Maverick is very insightful. The step-by-step approach makes it easy to follow for beginners. Looking forward to more posts on optimizing Hadoop setups! thanks for sharing.
ReplyDeleteData science course in Bangalore
Thank you for this detailed and insightful guide on deploying a Hadoop cluster on EC2/UEC! Your step-by-step approach and practical tips make it incredibly helpful for anyone navigating such deployments.
ReplyDeleteData science course in Lucknow
I love how you don’t just talk about the theory but actually offer practical advice!
ReplyDeleteData science courses in chennai
I loved how you presented this material! It was both educational and enjoyable to read. Keep up the great work
ReplyDeleteData science courses in Bangalore
Nice article, I got new information from your article, keep sharing.
ReplyDeleteIIM SKILLS Data Science Course Review
Great post! You've explained the process of deploying a Hadoop cluster on EC2/UEC very clearly. The step-by-step approach is really helpful for beginners as well as experienced users looking to optimize their setups. Thanks for sharing this valuable resource!
ReplyDeleteData science courses in Bangladesh
You have done a great job! Keep sharing such information.
ReplyDeleteDigital marketing courses in mumbai
The structure on this blog is well constructed, i really like it. I am looking for and I love to post a comment that "The content of your post is awesome". I really enjoyed reading this article. Thanks for sharing such detailed information.
ReplyDeletetechnical writing course
This is an excellent guide for setting up a Hadoop cluster on EC2/UEC using Puppet and Ubuntu Maverick. It walks you through the essential steps, from configuring the Cloud Conductor to deploying Hadoop components like the NameNode, JobTracker, and Worker nodes. Despite some minor bugs with Puppet stages and init scripts, the instructions provide solid workarounds to ensure a smooth deployment. Overall, a great resource for automating Hadoop cluster management in the cloud! Investment Banking Course
ReplyDeleteThis article offers an insightful guide on deploying a Hadoop cluster on EC2/UEC with Puppet and Ubuntu Maverick. digital marketing courses in delhi
ReplyDeleteDeploying a Hadoop cluster on EC2 using Puppet offers automated scalability and efficient resource management. Integrating it with Ubuntu Maverick ensures a streamlined setup with enhanced compatibility for big data processing.
ReplyDeleteData science courses in Mumbai
Data science courses in Mumbai
Name: INTERN NEEL
Email ID: internneel@gmail.com
Thank you so much for providing a great tutorial on Deploying a Hadoop cluster on EC2/UEC with Puppet and Ubuntu Maverick.
ReplyDeleteData Science Courses in Micronesia
https://iimskills.com/data-science-courses-in-micronesia/
Data Science Courses in Micronesia
"Fantastic tutorial on deploying a Hadoop cluster on EC2/UEC! Your step-by-step guide is incredibly detailed and helpful. Thanks for sharing your expertise, even years later, this post remains a valuable resource!"
ReplyDeletebusiness analyst course in bangalore
It looks like you’ve shared a guide for deploying a Hadoop cluster on EC2/UEC using Puppet on Ubuntu Maverick. Are you looking for help with troubleshooting, updating it for a more recent setup.
ReplyDeletedigital marketing course in nashik
Automate Hadoop cluster deployment on EC2/UEC using Puppet with Ubuntu Maverick for scalable, efficient, and streamlined big data processing.Medical Coding Course
ReplyDeleteThanks for sharing the step-by-step guide on deploying Hadoop Cluster on ec2uec. This a great resource for anyone looking to implement a secure and scalable analytics platform.
ReplyDeleteMedical Coding Courses in Chennai
Thank you for this detailed and insightful guide on deploying a Hadoop cluster on EC2/UEC! Your step-by-step approach and practical tips make it incredibly helpful for anyone navigating such deployments.
ReplyDeleteMedical Coding Courses in Kochi
This blog states about Deploying a Hadoop cluster on EC2/UEC with Puppet and Ubuntu Maverick. This is for the hadoop workers mostly.
ReplyDeleteMedical Coding Courses in Bangalore
Well-written and insightful. Keep up the good work
ReplyDeletehttps://iimskills.com/medical-coding-courses-in-delhi/
This article provides a comprehensive and detailed guide to deploying a Hadoop cluster on EC2 using Puppet and Ubuntu Maverick. It's fascinating to see how automation with Puppet simplifies the management of large-scale clusters, making it easier to set up and configure Hadoop components efficiently.
ReplyDeleteMedical Coding Course in Hyderabad
Thanks for sharing! This guide explains how to deploy a Hadoop cluster on EC2 using Puppet, with automation for efficient setup and configuration. It's practical and to the point!
ReplyDeleteMedical coding courses in Delhi/
"IIM SKILLS truly values its students' success. The instructors were always available to clear doubts, and they guided us even after course completion."
ReplyDelete"The course was flexible, which allowed me to learn at my own pace while balancing my work commitments. Highly recommend IIM SKILLS for anyone with a busy schedule."
Medical Coding Courses in Coimbatore
Learning how to make decisions under uncertainty was one of the key takeaways from IIM. This skill has been essential as I’ve navigated my career.
ReplyDeleteMedical Coding Courses in Chennai
Well explained how to deploy a Hadoop cluster on EC2 using Puppet, with automation for efficient setup and configurationThis article breaks down complex concepts really well. Excited to try out some of these tips! Medical Coding Courses in Delhi
ReplyDeleteThis post was so informative! I love how clearly you explained everything." Medical Coding Courses in Delhi
ReplyDeleteGreat post! Very well-explained and informative.
ReplyDeleteMedical Coding Courses in Delhi
Great post! You've explained the process of deploying a Hadoop cluster on EC2/UEC very clearly. The step-by-step approach is really helpful for beginners as well as experienced users looking to optimize their setups. Thanks for sharing this valuable resource!
ReplyDeletehttps://iimskills.com/medical-coding-courses-in-bangalore/
This is really a great information from your post.
ReplyDeletehttps://iimskills.com/medical-coding-courses-in-hyderabad/
I found it very useful and informative.
ReplyDeleteMedical Coding Courses in Delhi
Thanks for sharing such detailed information.
ReplyDeleteData Science Courses in India
This guide offers a powerful combination of automation and cloud infrastructure by using Puppet to deploy Hadoop on EC2/UEC. It’s a detailed, hands-on walkthrough perfect for DevOps and big data enthusiasts. Efficient, scalable, and well-structured—ideal for those seeking to streamline Hadoop cluster setups in cloud environments!
ReplyDeleteData Science Courses in India
This article about deploying a Hadoop cluster on EC2/UEC using Puppet and Ubuntu Maverick is a fascinating look back at the evolution of cloud infrastructure and big data deployment! It's a testament to how much things have progressed since the days of manually configuring Hadoop on cloud instances.
ReplyDeleteData Science Courses in India
Thanks for the detailed walkthrough on deploying a Hadoop cluster on EC2/UEC with Ambari! Your step-by-step guide makes a complex process much more approachable, especially for those new to cloud-based Hadoop deployments. This is a valuable resource for anyone looking to set up scalable big data environments. Appreciate you sharing your experience!
ReplyDeleteMedical Coding Courses in Delhi
Great detailed walkthrough on deploying a Hadoop cluster using Puppet on EC2 with Ubuntu Maverick! The automation with Puppet and integration with AWS services like S3 makes scaling and management much easier.
ReplyDeleteMedical Coding Courses in Delhi
This is an excellent and highly detailed walkthrough of deploying a Hadoop cluster on EC2 using Puppet and Ubuntu Maverick. It’s great to see how infrastructure automation can simplify what used to be a very hands-on and error-prone deployment process. Medical Coding Courses in Kochi
ReplyDeleteLearning how to make decisions under uncertainty was one of the key takeaways from IIM. This skill has been essential as I’ve navigated my career.
ReplyDeleteMedical Coding Courses in Delhi
I am looking for and I love to post a comment that "The content of your post is awesome". I really enjoyed reading this article. Thanks for sharing such detailed information.
ReplyDeleteMedical Coding Courses in Delhi
Thank you so much for sharing your thoughts on this. I was looking for more information , and this really helped!
ReplyDeleteMedical Coding Courses in Delhi
Very informative and well-explained article! Thanks for sharing such valuable insights.
ReplyDeleteMedical Coding Courses in Delhi
A well-orchestrated deployment of a Hadoop cluster using Puppet and EC2, showcasing strong automation principles. Minor service start issues are resolved with simple Puppet agent restarts.
ReplyDeleteMedical Coding Courses in Delhi
Great walkthrough, Automating Hadoop deployment using Puppet on EC2/UEC really simplifies what could otherwise be a complex setup.
ReplyDeleteMedical Coding Courses in Delhi
Great walkthrough! Using Puppet to automate Hadoop cluster deployment on EC2 with Ubuntu Maverick really streamlines the process. Very useful for anyone setting up scalable big data environments.
ReplyDeleteMedical Coding Courses in Delhi
Nice Post ! really enjoyed reading this article. Thanks for sharing such detailed information.
ReplyDeleteMedical Coding Courses in Delhi
Great step-by-step guide for deploying a Hadoop cluster on EC2/UEC with Puppet! The automation tips and troubleshooting advice are especially helpful. Thanks for sharing your expertise! If you’re looking to expand your skills, check out these Medical Coding Courses in Delhi.
ReplyDeleteIt is amazing and wonderful to visit your site .Thanks for sharing this.
ReplyDeleteMedical Coding Courses in Delhi
financial modeling courses in delhi
ReplyDeleteThis was such a helpful walkthrough! I’ve been exploring Hadoop setups, and your detailed steps for deploying a cluster on EC2/UEC really cleared things up. I especially liked how you broke down the network configuration part — that’s usually where I get stuck. Thanks for sharing this!
ReplyDeletefinancial modeling courses in delhi
This is a fantastic walkthrough—combining Hadoop, EC2/UEC, and Puppet with Ubuntu Maverick is no small feat, and you've laid it out clearly. I especially appreciate the use of Puppet for automating the deployment; it really streamlines what could otherwise be a tedious setup process.
Nicely explained
ReplyDeletefinancial modeling courses in delhi
Nice blog and informative post.
ReplyDeletefinancial modeling courses in delhi
I think we all wish to thank so many good articles, blog to share with us.
ReplyDeletehttps://iimskills.com/financial-modelling-course-in-delhi/
Your guide to deploying a Hadoop cluster on EC2/UEC is very well-detailed, especially for someone handling a setup for the first time. You’ve clearly covered the configurations, networking aspects, and key performance considerations. I appreciate that you also mentioned potential pitfalls like improper security group settings and resource bottlenecks — those save readers a lot of trial and error. This step-by-step structure really empowers readers to experiment confidently. It’s great to see such technical yet accessible documentation shared openly on the web for the benefit of the developer community.
ReplyDeletefinancial modeling courses in delhi
This tutorial offers a comprehensive guide to deploying a Hadoop 0.20.2 cluster on EC2/UEC, providing clear steps for setting up a scalable big data environment.
ReplyDeleteThe inclusion of both master and slave node configurations enhances the understanding of Hadoop's distributed architecture.
financial modeling courses in delhi
Clear, practical, and easy to follow—thanks for sharing
ReplyDeletefinancial modeling courses in delhi
This guide walks you through deploying a Hadoop 0.20.2 cluster on EC2 or UEC. It gives step-by-step instructions for creating a scalable big data setup. Both master and slave node configurations are included, making it easier to understand how Hadoop’s distributed system works.
ReplyDeletefinancial modeling courses in delhi
Thanks for sharing such a detailed guide on deploying a Hadoop cluster with Puppet on EC2. The step-by-step explanation and sample configurations make it much easier to understand the setup process. Really helpful for anyone working with cloud-based Hadoop clusters!
ReplyDeletefinancial modeling courses in delhi
Appreciate you sharing such an in-depth guide on setting up a Hadoop cluster using Puppet on EC2. The detailed walkthrough and sample configurations simplify the deployment process significantly. This is a great resource for anyone working with Hadoop clusters in the cloud!
ReplyDeletefinancial modeling courses in delhi
Fantastic post! Your insights are genuinely inspiring and provide a much-needed boost.
ReplyDeleteVISA Management Courses in Delhi