A Hadoop Cluster running on EC2/UEC deployed by puppet on Ubuntu Maverick.
How it works
The
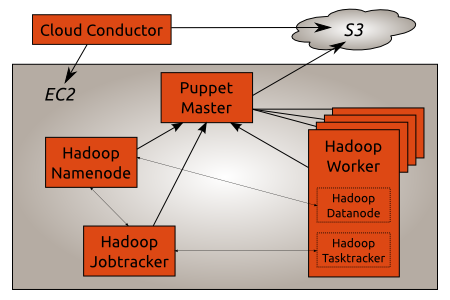
Cloud Conductor is located outside the AWS infrastructure as it needs AWS credentials to start new instances. The Puppet Master runs in EC2 and uses S3 to check which clients it should accept.
The Hadoop Namenode, Jobtracker and Worker are also running in EC2. The Puppet Master automatically configures them so that each Worker can connect to the Namenode and Jobtracker.
The Puppet Master uses
Stored Configuration to distribute configuration between all the Hadoop components. For example the Namenode IP address is automatically pushed to the Jobtracker and the Worker nodes so that they can connect to the Namenode.
Ubuntu Maverick is used since Puppet 2.6 is required. The excellent
Cloudera CDH3 Beta2 packages provide the base Hadoop foundation.
Puppet recipes and the Cloud Conductor scripts are available in a
bzr branch on Launchpad.
Setup the Cloud Conductor
The first part of the Cloud Conductor is the
start_instance.py script. It takes care of starting new instances in EC2 and registering them in S3. Its configuration lives in
start_instance.yaml. Both files are located in the
conductor directory of the bzr branch.
The following options are available on the cloud conductor:
- s3_bucket_name: Sets the name of the S3 bucket used to store the list of instances started by the Cloud Conductor. The Puppet Master uses the same bucket to check which Puppet Client should be accepted.
- ami_id: Sets the id of the AMI the Cloud Conductor will use to start new instances.
- cloud_init: Sets specific cloud-init parameters. All of the puppet client configuration is defined here.Public ssh keys (for example from Launchpad) can be configured using the ssh_import_id option. The cloud-init documentation has more information [1] about what can be configured when starting new instances.
A sample
start_instance.yaml file looks like this:
# Name of the S3 bucket to use to store the certname of started instances
s3_bucket_name: mathiaz-hadoop-cluster
# Base AMI id to use to start all instances
ami_id: ami-c210e5ab
# Extra information passed to cloud-init when starting new instances
# see cloud-init documentation for available options.
cloud_init: &site-cloud-init
ssh_import_id: mathiaz
Once the Cloud Conductor is configured a Puppet Master can be started:
./start_instance.py puppetmaster
Setup the Puppet Master
Once the instance has started and its ssh fingerprints can be verified the puppet recipes are deployed on the Puppet Master:
bzr branch lp:~mathiaz/+junk/hadoop-cluster-puppet-conf ~/puppet/
sudo mv /etc/puppet/ /etc/old.puppet
sudo mv ~/puppet/ /etc/
The S3 bucket name is set in the Puppet Master configuration
/etc/puppet/manifests/puppetmaster.pp:
node default {
class {
"puppet::ca":
node_bucket => "https://mathiaz-hadoop-cluster.s3.amazonaws.com";
}
}
And finally the Puppet Master installation can be completed by puppet itself:
sudo puppet apply /etc/puppet/manifests/puppetmaster.pp
A Puppet Master is now running into EC2 with all the recipes required to deploy the different components of a Hadoop Cluster.
Update the Cloud Conductor configuration
Since the Cloud Conductor starts instances that will connect to the Puppet Master it needs to know some information about the Puppet Master:
- the Puppet Master internal IP address or DNS name. For example the DNS name of the instance (which is the FQDN) can be used.
- the Puppet Master certificate (located in /var/lib/puppet/ssl/ca/ca_crt.pem):
On the Cloud Conductor the information gathered on the Puppet Master is added to
start_instance.yaml:
agent:
# Puppet server hostname or IP
# In EC2 the Private DNS of the instance should be used
server: domU-12-31-38-00-35-98.compute-1.internal
# NB: the certname will automatically be added by start_instance.py
# when a new instance is started.
# Puppetmaster ca certificate
# located in /var/lib/puppet/ssl/ca/ca_crt.pem on the puppetmaster system
ca_cert: |
-----BEGIN CERTIFICATE-----
MIICFzCCAYCgAwIBAgIBATANBgkqhkiG9w0BAQUFADAUMRIwEAYDVQQDDAlQdXBw
[ ... ]
k0r/nTX6Tmr8TTU=
-----END CERTIFICATE-----
Start the Hadoop Namenode
Once the Puppet Master and Cloud Conductor are configured the Hadoop Cluster can be deployed. First in line is the Hadoop Namenode:
./start_instance.py namenode
After a few minutes the Namenode puppet client requests a certificate:
puppet-master[7397]: Starting Puppet master version 2.6.1
puppet-master[7397]: 53b0b7bf-723c-4a0f-b4b1-082ebec84041 has a waiting certificate request
The Master signs the CSR:
CRON[8542]: (root) CMD (/usr/local/bin/check_csr https://mathiaz-hadoop-cluster.s3.amazonaws.com)
check_csr[8543]: INFO: Signing request: 53b0b7bf-723c-4a0f-b4b1-082ebec84041
And finally the Master compiles the manifest for the Namenode:
node_classifier[8989]: DEBUG: Checking url https://mathiaz-hadoop-cluster.s3.amazonaws.com/53b0b7bf-723c-4a0f-b4b1-082ebec84041
node_classifier[8989]: INFO: Getting node configuration: 53b0b7bf-723c-4a0f-b4b1-082ebec84041
node_classifier[8989]: DEBUG: Node configuration (53b0b7bf-723c-4a0f-b4b1-082ebec84041): classes: ['hadoop::namenode']
puppet-master[7397]: Puppet::Parser::AST::Resource failed with error ArgumentError: Could not find stage hadoop-base specified by Class[Hadoop::Base] at /etc/puppet/modules/hadoop/manifests/init.pp:142 on node 53b0b7bf-723c-4a0f-b4b1-082ebec84041
Unfortunately there is a bug related to puppet stages. As a workaround the puppet agent can be restarted:
sudo /etc/init.d/puppet restart
Looking at the syslog file on the Namenode the Puppet Agent installs and configures the Hadoop Namenode:
puppet-agent[1795]: Starting Puppet client version 2.6.1
puppet-agent[1795]: (/Stage[apt]/Hadoop::Apt/Apt::Key[cloudera]/File[/etc/apt/cloudera.key]/ensure) defined content as '{md5}dc59b632a1ce2ad325c40d0ba4a4927e'
puppet-agent[1795]: (/Stage[apt]/Hadoop::Apt/Apt::Key[cloudera]/Exec[import apt key cloudera]) Triggered 'refresh' from 1 events
puppet-agent[1795]: (/Stage[apt]/Hadoop::Apt/Apt::Sources_list[canonical]/File[/etc/apt/sources.list.d/canonical.list]/ensure) created
puppet-agent[1795]: (/Stage[apt]/Hadoop::Apt/Apt::Sources_list[cloudera]/File[/etc/apt/sources.list.d/cloudera.list]/ensure) created
puppet-agent[1795]: (/Stage[apt]/Apt::Apt/Exec[apt-get_update]) Triggered 'refresh' from 3 events
The first stage of the puppet run sets up the Canonical partner archive and the Cloudera archive. The Sun JVM is pulled from the Canonical archive while Hadoop packages are downloaded from the Cloudera archive.
The following stage creates a common Hadoop configuration:
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/var/cache/debconf/sun-java6.seeds]/ensure) defined content as '{md5}1e3a7ac4c2dc9e9c3a1ae9ab2c040794'
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/Package[sun-java6-bin]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/Package[hadoop-0.20]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/var/lib/hadoop-0.20/dfs]/ensure) created
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/etc/hadoop-0.20/conf.puppet]/ensure) created
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/etc/hadoop-0.20/conf.puppet/hdfs-site.xml]/ensure) defined content as '{md5}1f9788fceffdd1b2300c06160e7c364e'
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/Exec[/usr/sbin/update-alternatives --install /etc/hadoop-0.20/conf hadoop-0.20-conf /etc/hadoop-0.20/conf.puppet 15]) Triggered 'refresh' from 1 events
puppet-agent[1795]: (/Stage[hadoop-base]/Hadoop::Base/File[/etc/default/hadoop-0.20]/content) content changed '{md5}578894d1b3f7d636187955c15b8edb09' to '{md5}ecb699397751cbaec1b9ac8b2dd0b9c3'
Finally the Hadoop Namenode is configured:
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/Package[hadoop-0.20-namenode]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/File[hadoop-core-site]/ensure) defined content as '{md5}2f2445bf3d4e26f5ceb3c32047b19419'
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/File[/var/lib/hadoop-0.20/dfs/name]/ensure) created
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/Exec[format-dfs]) Triggered 'refresh' from 1 events
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/Service[hadoop-0.20-namenode]/ensure) ensure changed 'stopped' to 'running'
puppet-agent[1795]: (/Stage[main]/Hadoop::Namenode/Service[hadoop-0.20-namenode]) Failed to call refresh: Could not start Service[hadoop-0.20-namenode]: Execution of '/etc/init.d/hadoop-0.20-namenode start' returned 1: at /etc/puppet/modules/hadoop/manifests/init.pp:177
There is another bug in the Hadoop init script this time: the Namenode cannot be started. The puppet agent can be restarted or the next puppet run will start it:
sudo /etc/init.d/puppet restart
The Namenode daemon is running and logs information to its log file in
/var/log/hadoop/hadoop-hadoop-namenode-*.log:
[...]
INFO org.apache.hadoop.hdfs.server.namenode.NameNode: Web-server up at: 0.0.0.0:50070
[...]
INFO org.apache.hadoop.ipc.Server: IPC Server handler 9 on 8200: starting
INFO org.apache.hadoop.ipc.Server: IPC Server handler 8 on 8200: starting
Start the Hadoop Jobtracker
The next component to start is the Hadoop Jobtracker:
./start_instance.py jobtracker
After some time the Puppet Master compiles the Jobtracker manifest:
DEBUG: Checking url https://mathiaz-hadoop-cluster.s3.amazonaws.com/2faa4de9-c708-45ab-a515-ae041a9d0239
node_classifier[30683]: INFO: Getting node configuration: 2faa4de9-c708-45ab-a515-ae041a9d0239
node_classifier[30683]: DEBUG: Node configuration (2faa4de9-c708-45ab-a515-ae041a9d0239): classes: ['hadoop::jobtracker']
puppet-master[23542]: Compiled catalog for 2faa4de9-c708-45ab-a515-ae041a9d0239 in environment production in 2.00 seconds
On the instance the puppet agent configures the Hadoop Jobtracker:
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/File[hadoop-mapred-site]/ensure) defined content as '{md5}af3b65a08df03e14305cc5fd56674867'
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/File[hadoop-core-site]/ensure) defined content as '{md5}2f2445bf3d4e26f5ceb3c32047b19419'
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/Package[hadoop-0.20-jobtracker]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/Service[hadoop-0.20-jobtracker]/ensure) ensure changed 'stopped' to 'running'
puppet-agent[1035]: (/Stage[main]/Hadoop::Jobtracker/Service[hadoop-0.20-jobtracker]) Failed to call refresh: Could not start Service[hadoop-0.20-jobtracker]: Execution of '/etc/init.d/hadoop-0.20-jobtracker start' returned 1: at /etc/puppet/modules/hadoop/manifests/init.pp:135
There is the same bug in the init script. Let's restart the puppet agent:
sudo /etc/init.d/puppet restart
The Jobtracker connects to the Namenode and error messages are logged on a regular basis to both the Namenode and Jobtracker log files:
INFO org.apache.hadoop.ipc.Server: IPC Server handler 7 on 8200, call
addBlock(/hadoop/mapred/system/jobtracker.info, DFSClient_-268101966, null)
from 10.122.183.121:54322: error: java.io.IOException: File
/hadoop/mapred/system/jobtracker.info could only be replicated to 0 nodes,
instead of 1
java.io.IOException: File /hadoop/mapred/system/jobtracker.info could only be
replicated to 0 nodes, instead of 1
This is normal as there aren't any Datanode daemon available for data replication.
Start Hadoop workers
It's now time to start the Hadoop Worker to get an operational Hadoop Cluster:
./start_instance.py worker
The Hadoop Worker holds both a Data node and a Task tracker. The Puppet agent configures them to talk to the Namenode and Job tracker respectively.
After some time the Puppet Master compiles the catalog for the Hadoop Worker:
node_classifier[8368]: DEBUG: Checking url https://mathiaz-hadoop-cluster.s3.amazonaws.com/b72a8f4d-55e6-4059-ac4b-26927f1a1016
node_classifier[8368]: INFO: Getting node configuration: b72a8f4d-55e6-4059-ac4b-26927f1a1016
node_classifier[8368]: DEBUG: Node configuration (b72a8f4d-55e6-4059-ac4b-26927f1a1016): classes: ['hadoop::worker']
puppet-master[23542]: Compiled catalog for b72a8f4d-55e6-4059-ac4b-26927f1a1016 in environment production in 0.18 seconds
On the instance the puppet agent installs the Hadoop worker:
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/File[hadoop-mapred-site]/ensure) defined content as '{md5}af3b65a08df03e14305cc5fd56674867'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Package[hadoop-0.20-datanode]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/File[/var/lib/hadoop-0.20/dfs/data]/ensure) created
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Package[hadoop-0.20-tasktracker]/ensure) ensure changed 'purged' to 'latest'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/File[hadoop-core-site]/ensure) defined content as '{md5}2f2445bf3d4e26f5ceb3c32047b19419'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Service[hadoop-0.20-datanode]/ensure) ensure changed 'stopped' to 'running'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Service[hadoop-0.20-datanode]) Failed to call refresh: Could not start Service[hadoop-0.20-datanode]: Execution of '/etc/init.d/hadoop-0.20-datanode start' returned 1: at /etc/puppet/modules/hadoop/manifests/init.pp:103
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Service[hadoop-0.20-tasktracker]/ensure) ensure changed 'stopped' to 'running'
puppet-agent[1030]: (/Stage[main]/Hadoop::Worker/Service[hadoop-0.20-tasktracker]) Failed to call refresh: Could not start Service[hadoop-0.20-tasktracker]: Execution of '/etc/init.d/hadoop-0.20-tasktracker start' returned 1: at /etc/puppet/modules/hadoop/manifests/init.pp:103
Again the same init script bug - let's restart the puppet agent:
sudo /etc/init.d/puppet restart
Once the worker is installed the Datanode daemon connects to the Namenode:
INFO org.apache.hadoop.hdfs.StateChange: BLOCK* NameSystem.registerDatanode: node registration from 10.249.187.5:50010 storage DS-2066068566-10.249.187.5-50010-1285276011214
INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/10.249.187.5:50010
Similarly the Task Tracker daemon registers itself with the Jobtracker:
INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/domU-12-31-39-03-B8-F7.compute-1.internal
The Hadoop Cluster is up and running.
Conclusion
Once the initial setup of the Puppet master is done and the Hadoop Namenode and Jobtracker are up and running adding new Hadoop Workers is
just one command:
./start_instance.py worker
Puppet automatically configures them to join the Hadoop Cluster.


{kind=link}